O algoritmo mais rápido do oeste
Dia desses um amigo me passou um probleminha bem divertido. O enunciado é simples: dado um vetor ordenado, construa uma binary search tree, balanceada, com os mesmos elementos do vetor. Esse problema tem uma solução trivial em O(n log n) e uma solução esperta em O(n), mas eu acabei achando uma terceira solução, com o algoritmo mais rápido do oeste: ele roda em O(0)!

Vamos revisar as respostas tradicionais antes. A solução trivial é usar uma árvore binária auto-balanceante, como a AVL ou a Red-Black, e inserir os elementos nela, um por um. Como você vai inserir n elementos e o custo de inserção é O(log n), então o total desse algoritmo é O(n log n).
Mas fazendo dessa maneira, você não está usando a informação de que o vetor estava ordenado. Com uma recursão simples você consegue aproveitar esse fato, e construir a árvore em apenas O(n). Um exemplo em python é assim:
Aparentemente, essa solução é ótima. Se você vai criar uma estrutura de dados nova usando os dados da antiga, o mínimo de trabalho que você precisa é copiar os elementos de uma pra outra, e isso limita em O(n) certo? Quase! Você pode contornar essa limitação se usar uma estrutura de dados implícita, e é isso que vamos tentar fazer.
Para usar o vetor ordenado original como uma estrutura implícita, nós precisamos criar um isomorfismo entre o vetor ordenado e a binary search tree. Se for possivel criar esse isomorfismo, então na verdade eu não preciso fazer nada pra converter o vetor, ele já é equivalente à árvore. E um algoritmo que não faz nada é um algoritmo O(0)! Eu poderia chamar essa estrutura de dados nova de Implicit Balanced Binary Search Tree, mas é muito comprido, então vou chamá-la de Cactus Binário (apropriado, daqui em diante as coisas vão ficar espinhosas).
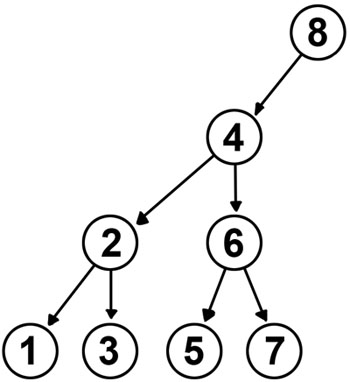
Mas vamos ao isomorfismo então. Como o vetor está ordenado, então os valores dos elementos em si não importam muito, e nós podemos trabalhar só com os índices, sem perda de generalidade. Além disso, para as demonstrações ficarem mais simples, vamos dividir em dois casos. Digamos que o tamanho do vetor é N, então o primeiro caso que vamos tratar é quando N pode ser escrito como 2h-1 para algum h>0. Nesse caso, o Cactus Binário é uma árvore perfeita (todas as folhas estão no mesmo nível e todos os nós internos tem dois filhos):
-743037.jpg)
Para criar o isomorfismo, eu preciso fornecer duas funções que, para um dado índice, me retornem o índice do filho à esquerda e do filho à direita. Depois de pensar um pouco, acabei chegando nas funções abaixo:
left(x) = x - (x & (-x)) / 2
right(x) = x + (x & (-x)) / 2
Isso é mágica? Não, é matemática! Para entender porque as expressões funcionam, é só olhar para a árvore anterior usando a visão além do alcance:
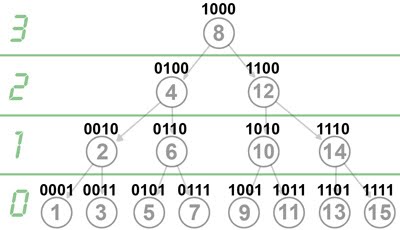
Olha só que bacana, quando você olha para os índices da árvore em binário, parece que o nível em que está o índice é igual ao número de zeros no final da representação binária dele. Na verdade, nós podemos provar isso, usando indução na altura da árvore.
Vejamos: para uma árvore de altura unitária, o único elemento é o 1, que está no nível zero e tem 0 bits zero no final, então a base de indução está ok. Se a árvore tem altura h, então ela tem 2h-1 elementos. O elemento central é o 2h-1, que tem h-1 zeros no final e está no nível h-1. A sub-árvore da esquerda é uma árvore balanceada de tamanho 2h-1-1, que funciona pela hipótese de indução. A sub-árvore da direita é igual à da esquerda, se você ligar o bit mais significativo de cada índice. Setar o bit mais à esquerda não muda a quantidade de bits zero à direita, então podemos usar a hipótese de indução novamente, e pronto: QED.
Agora ficou fácil achar a fórmula né? Se você tem um índice x no nivel h, então o filho à esquerda é o maior número com h-1 zeros à direita que seja menor que x, e o análogo vale para o filho à direita. Ou seja, pra descer do nível h para o nível h-1 pela esquerda, basta subtrair 2h-1 (ou somar, se for pela direita).
E computacionalmente como eu faço isso? Basta achar o bit 1 mais à direita do número, dividir isso por dois e subtrair do número original. Para achar o primeiro bit 1, o truque é calcular x & (-x). Vamos provar: pela definição de complemento de dois, negar é o mesmo que inverter e somar um. Se o número em binário for algo do tipo xxxx10000, negado ele fica yyyy01111, e quando você soma um, o carry propaga até bater no zero, ficando yyyy10000. Quando você faz o AND, os primeiros bits dão zero porque o AND de um bit e seu complemento é sempre zero, e os últimos bits dão zero porque o AND de qualquer bit com zero dá zero. Sobra só o primeiro bit 1 à direita, QED.
Juntando tudo agora as duas fórmulas são evidentes. Mas pra completar o isomorfismo eu ainda preciso de uma fórmula que me indique onde está a raiz da árvore. A fórmula em si é simples: a raiz é a maior potência de dois menor ou igual ao tamanho do vetor, ou seja, basta achar o primeiro bit 1 à esquerda do tamanho.
Para achar o primeiro bit 1 à esquerda não tem nenhum truque tão simples quanto à direita, mas felizmente existe uma alternativa: os processadores x86 possuem um opcode meio desconhecido chamado BSR (bit scan reverse), que retorna exatamente onde está esse bit à esquerda. Em processadores bons, como o Core 2 Duo, o BSR é uma operação O(1), mas isso não é verdade em todos os processadores (por exemplo, não é verdade nos AMDs). Se você não tiver o BSR por hardware, pode fazer uma busca binária nos bits do número, que é uma operação O(log log n).
Isso conclui o primeiro caso. Vamos ver agora o que acontece quando o tamanho é um número qualquer. O pior caso do algoritmo é quando o tamanho é uma potência de dois, e o Cactus Binário fica assim:
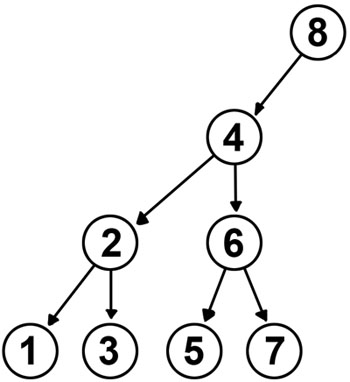
Uepa! Essa árvore está balanceada? Bem, depende da sua definição de balanceada. Nessa árvore, o maior caminho entre a raiz e uma folha é 4, o que parece muito. Mas, na verdade, não dá criar uma árvore que tenha um caminho máximo menor. Se o caminho máximo fosse 3, então a árvore poderia ter no máximo 7 elementos, e pelo princípio da casa dos pombos a árvore de tamanho 8 com caminho máximo 3 é impossível. De fato, se você tentar balancear mais a árvore, o melhor que você consegue é algo assim:
-745411.jpg)
Logo, o caminho máximo do Cactus Binário é o mesmo caminho máximo da árvore balanceada. Note, entretanto, que isso é melhor que as árvores auto-balanceantes! O caminho máximo da AVL, no pior caso, é 1.44log(n), e o da Red-Black é 2log(n), ambos maiores que o Cactus Binário.
Com isso, nós provamos o isomorfismo para os dois casos, e o algoritmo O(0) realmente funciona! Mas a grande dúvida agora é: ele serve pra alguma coisa? Na verdade, a grande vantagem da árvore binária é que ela faz inserções em O(log n), enquanto que uma inserção no Cactus Binário é apenas O(n). Por isso, nas aplicações práticas da vida real a árvore binária ganha. Aparentemente, a única utilidade do Cactus Binário é para escrever blog posts :)

Vamos revisar as respostas tradicionais antes. A solução trivial é usar uma árvore binária auto-balanceante, como a AVL ou a Red-Black, e inserir os elementos nela, um por um. Como você vai inserir n elementos e o custo de inserção é O(log n), então o total desse algoritmo é O(n log n).
Mas fazendo dessa maneira, você não está usando a informação de que o vetor estava ordenado. Com uma recursão simples você consegue aproveitar esse fato, e construir a árvore em apenas O(n). Um exemplo em python é assim:
def build_tree(vector):
def partition(start, end):
if (end < start):
return None
middle = start + (end-start) / 2
return (vector[middle],
partition(start, middle-1),
partition(middle+1, end))
return partition(0, len(vector) - 1)Aparentemente, essa solução é ótima. Se você vai criar uma estrutura de dados nova usando os dados da antiga, o mínimo de trabalho que você precisa é copiar os elementos de uma pra outra, e isso limita em O(n) certo? Quase! Você pode contornar essa limitação se usar uma estrutura de dados implícita, e é isso que vamos tentar fazer.
Para usar o vetor ordenado original como uma estrutura implícita, nós precisamos criar um isomorfismo entre o vetor ordenado e a binary search tree. Se for possivel criar esse isomorfismo, então na verdade eu não preciso fazer nada pra converter o vetor, ele já é equivalente à árvore. E um algoritmo que não faz nada é um algoritmo O(0)! Eu poderia chamar essa estrutura de dados nova de Implicit Balanced Binary Search Tree, mas é muito comprido, então vou chamá-la de Cactus Binário (apropriado, daqui em diante as coisas vão ficar espinhosas).
Mas vamos ao isomorfismo então. Como o vetor está ordenado, então os valores dos elementos em si não importam muito, e nós podemos trabalhar só com os índices, sem perda de generalidade. Além disso, para as demonstrações ficarem mais simples, vamos dividir em dois casos. Digamos que o tamanho do vetor é N, então o primeiro caso que vamos tratar é quando N pode ser escrito como 2h-1 para algum h>0. Nesse caso, o Cactus Binário é uma árvore perfeita (todas as folhas estão no mesmo nível e todos os nós internos tem dois filhos):
-743058.jpg)
Para criar o isomorfismo, eu preciso fornecer duas funções que, para um dado índice, me retornem o índice do filho à esquerda e do filho à direita. Depois de pensar um pouco, acabei chegando nas funções abaixo:
left(x) = x - (x & (-x)) / 2
right(x) = x + (x & (-x)) / 2
Isso é mágica? Não, é matemática! Para entender porque as expressões funcionam, é só olhar para a árvore anterior usando a visão além do alcance:
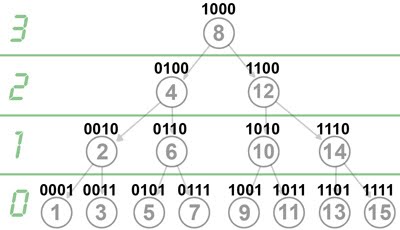
Olha só que bacana, quando você olha para os índices da árvore em binário, parece que o nível em que está o índice é igual ao número de zeros no final da representação binária dele. Na verdade, nós podemos provar isso, usando indução na altura da árvore.
Vejamos: para uma árvore de altura unitária, o único elemento é o 1, que está no nível zero e tem 0 bits zero no final, então a base de indução está ok. Se a árvore tem altura h, então ela tem 2h-1 elementos. O elemento central é o 2h-1, que tem h-1 zeros no final e está no nível h-1. A sub-árvore da esquerda é uma árvore balanceada de tamanho 2h-1-1, que funciona pela hipótese de indução. A sub-árvore da direita é igual à da esquerda, se você ligar o bit mais significativo de cada índice. Setar o bit mais à esquerda não muda a quantidade de bits zero à direita, então podemos usar a hipótese de indução novamente, e pronto: QED.
Agora ficou fácil achar a fórmula né? Se você tem um índice x no nivel h, então o filho à esquerda é o maior número com h-1 zeros à direita que seja menor que x, e o análogo vale para o filho à direita. Ou seja, pra descer do nível h para o nível h-1 pela esquerda, basta subtrair 2h-1 (ou somar, se for pela direita).
E computacionalmente como eu faço isso? Basta achar o bit 1 mais à direita do número, dividir isso por dois e subtrair do número original. Para achar o primeiro bit 1, o truque é calcular x & (-x). Vamos provar: pela definição de complemento de dois, negar é o mesmo que inverter e somar um. Se o número em binário for algo do tipo xxxx10000, negado ele fica yyyy01111, e quando você soma um, o carry propaga até bater no zero, ficando yyyy10000. Quando você faz o AND, os primeiros bits dão zero porque o AND de um bit e seu complemento é sempre zero, e os últimos bits dão zero porque o AND de qualquer bit com zero dá zero. Sobra só o primeiro bit 1 à direita, QED.
Juntando tudo agora as duas fórmulas são evidentes. Mas pra completar o isomorfismo eu ainda preciso de uma fórmula que me indique onde está a raiz da árvore. A fórmula em si é simples: a raiz é a maior potência de dois menor ou igual ao tamanho do vetor, ou seja, basta achar o primeiro bit 1 à esquerda do tamanho.
Para achar o primeiro bit 1 à esquerda não tem nenhum truque tão simples quanto à direita, mas felizmente existe uma alternativa: os processadores x86 possuem um opcode meio desconhecido chamado BSR (bit scan reverse), que retorna exatamente onde está esse bit à esquerda. Em processadores bons, como o Core 2 Duo, o BSR é uma operação O(1), mas isso não é verdade em todos os processadores (por exemplo, não é verdade nos AMDs). Se você não tiver o BSR por hardware, pode fazer uma busca binária nos bits do número, que é uma operação O(log log n).
Isso conclui o primeiro caso. Vamos ver agora o que acontece quando o tamanho é um número qualquer. O pior caso do algoritmo é quando o tamanho é uma potência de dois, e o Cactus Binário fica assim:
Uepa! Essa árvore está balanceada? Bem, depende da sua definição de balanceada. Nessa árvore, o maior caminho entre a raiz e uma folha é 4, o que parece muito. Mas, na verdade, não dá criar uma árvore que tenha um caminho máximo menor. Se o caminho máximo fosse 3, então a árvore poderia ter no máximo 7 elementos, e pelo princípio da casa dos pombos a árvore de tamanho 8 com caminho máximo 3 é impossível. De fato, se você tentar balancear mais a árvore, o melhor que você consegue é algo assim:
-745414.jpg)
Logo, o caminho máximo do Cactus Binário é o mesmo caminho máximo da árvore balanceada. Note, entretanto, que isso é melhor que as árvores auto-balanceantes! O caminho máximo da AVL, no pior caso, é 1.44log(n), e o da Red-Black é 2log(n), ambos maiores que o Cactus Binário.
Com isso, nós provamos o isomorfismo para os dois casos, e o algoritmo O(0) realmente funciona! Mas a grande dúvida agora é: ele serve pra alguma coisa? Na verdade, a grande vantagem da árvore binária é que ela faz inserções em O(log n), enquanto que uma inserção no Cactus Binário é apenas O(n). Por isso, nas aplicações práticas da vida real a árvore binária ganha. Aparentemente, a única utilidade do Cactus Binário é para escrever blog posts :)
Marcadores: assembly, binário, code, complexidade, grafos, math, python
postado por Ricardo Bittencourt às
00:23
|
11 Comentários
Links para esta postagem
![]()








 Para uma força inversamente quadrática, a órbita é circular, como esperado pela Lei da Gravidade.
Para uma força inversamente quadrática, a órbita é circular, como esperado pela Lei da Gravidade. Já uma força inversamente cúbica gera uma espiral. Essa força é fraquinha demais pra manter uma órbita, e o planeta vai aos poucos se afastando.
Já uma força inversamente cúbica gera uma espiral. Essa força é fraquinha demais pra manter uma órbita, e o planeta vai aos poucos se afastando. Uma força inversamente linear demora para estabilizar, mas acaba fazendo uma órbita circular também.
Uma força inversamente linear demora para estabilizar, mas acaba fazendo uma órbita circular também. E uma força constante, independente da distância? Ela também termina numa órbita circular, o que pra mim faz sentido. O planeta se move até o ponto onde a força constante é igual à centrípeta.
E uma força constante, independente da distância? Ela também termina numa órbita circular, o que pra mim faz sentido. O planeta se move até o ponto onde a força constante é igual à centrípeta. Agora vamos sacanear e colocar uma força senoidal só pra ver o que acontece. Ele não diverge, mas faz uma órbita muito doida. Provavelmente é um atrator estranho.
Agora vamos sacanear e colocar uma força senoidal só pra ver o que acontece. Ele não diverge, mas faz uma órbita muito doida. Provavelmente é um atrator estranho.